










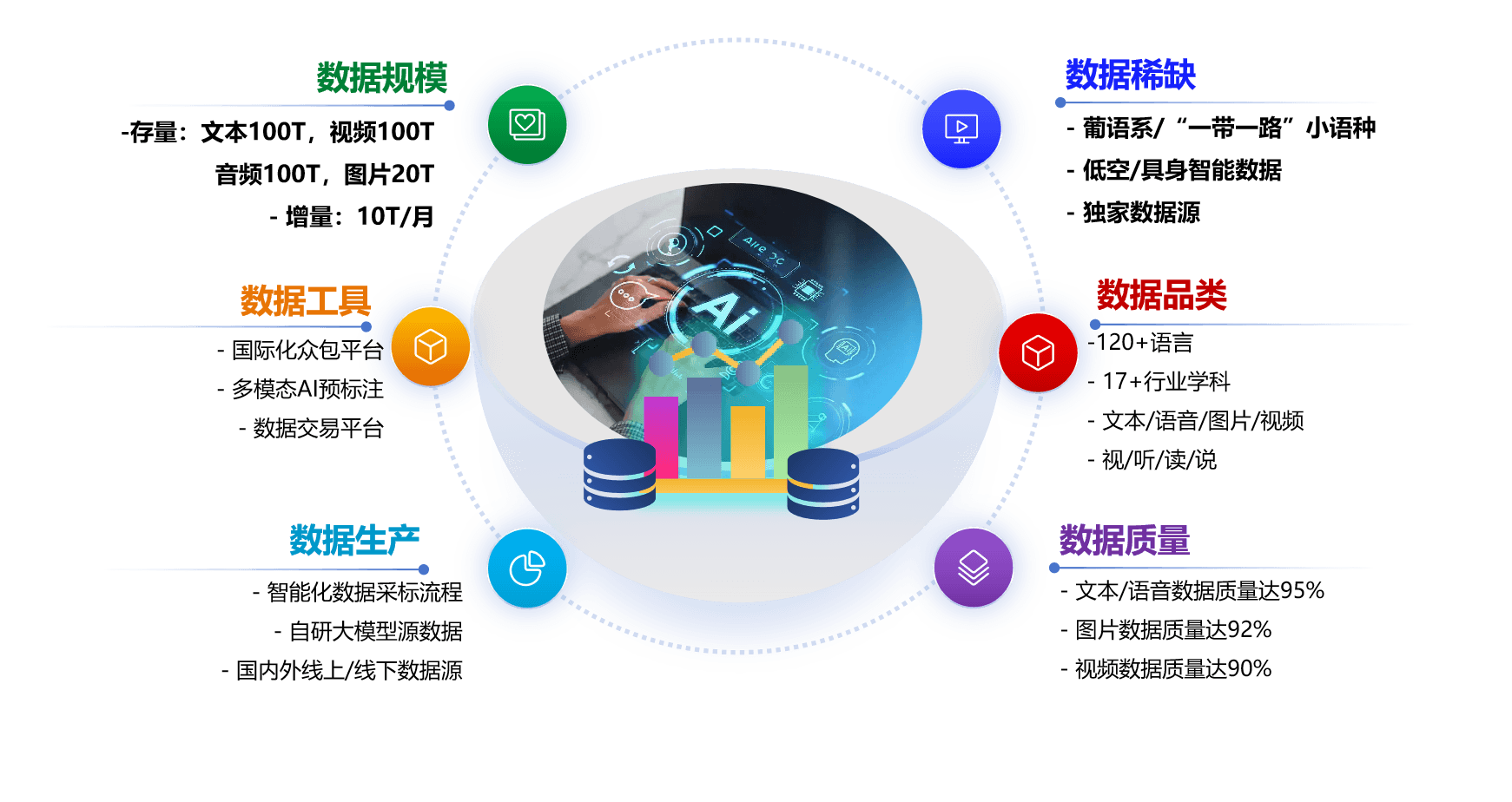
数据资源综合概览
庞大的数据规模:文本、视频、音频各100T,图片20T,每月新增10T
专业的数据工具:国际化众包平台、多模态AI预标注、数据交易平台
高质量数据:文本/语音数据质量达95%,图片92%,视频90%
详细信息
📦数据规模
- 存量:文本100T,视频100T,音频100T,图片20T
- 增量:10T/月
从数据规模来看,文本、视频、音频均达到100T的存量,图片也有20T,且每月还以10T的速度增长,这表明数据资源在数量上十分丰富,能够为各类数据相关应用和研究提供充足的基础素材,无论是大规模的数据分析还是模型训练,都有足够的数据支撑。
🔧数据工具
- 国际化众包平台
- 多模态AI预标注
- 数据交易平台
配备的国际化众包平台,有助于汇聚全球的人力来进行数据标注等工作,能提高数据处理的效率和多样性;多模态AI预标注工具可以利用人工智能技术自动对数据进行初步标注,减少人工标注的工作量,提升数据处理的智能化水平;数据交易平台则为数据的流通和共享提供了渠道,有利于数据价值的最大化利用,促进数据生态的发展。
⚙️数据生产
- 智能化数据采标流程
- 自研大模型源数据
- 国内外线上/线下数据源
智能化的数据采标流程,实现了数据采集和标注的自动化、高效化,能保证数据生产的质量和效率;自研大模型源数据,说明在数据生产方面有自主研发的能力,可根据自身需求定制化生产数据,满足特定大模型训练等场景的需求;同时依托国内外线上线下的数据源,能获取到更广泛、更多样化的数据,进一步丰富数据资源库。
🏷️数据品类
- 120+语言
- 17+行业学科
- 文本/语音/图片/视频
- 视/听/读/说
数据品类覆盖了120多种语言和17多个行业学科,还有文本、语音、图片、视频等多种数据形式以及视、听、读、说等多维度的数据,这意味着数据资源具有极强的多样性和全面性,能够满足不同领域、不同应用场景下对数据的需求,无论是跨语言的研究,还是多行业的数据分析,都能找到合适的数据资源。
✅数据质量
- 文本/语音数据质量达95%
- 图片数据质量达92%
- 视频数据质量达90%
文本和语音数据质量达到95%,图片为92%,视频也有90%,这样的高质量数据,对于依赖数据质量的应用,如自然语言处理、计算机视觉等领域的模型训练,能够极大地提高模型的准确性和性能,减少因数据质量问题带来的误差,为后续的数据应用和分析提供可靠的基础。
⚠️数据稀缺
- 葡语系/"一带一路"小语种
- 低空/具身智能数据
- 独家数据源
葡语系以及“一带一路”相关的小语种数据稀缺,在全球化的背景下,这些小语种数据对于开展与葡语国家以及“一带一路”沿线国家的交流合作等工作十分重要,稀缺会限制相关业务的拓展;低空和具身智能数据的稀缺,会影响低空领域以及具身智能相关技术的发展,因为缺乏足够的数据来进行研究和模型训练;独家数据源的稀缺,使得在一些需要特定独家数据的场景下,难以获取到关键数据,可能会制约相关创新和应用的开展。不过,这也从侧面反映出在这些领域存在着数据挖掘和发展的机会。